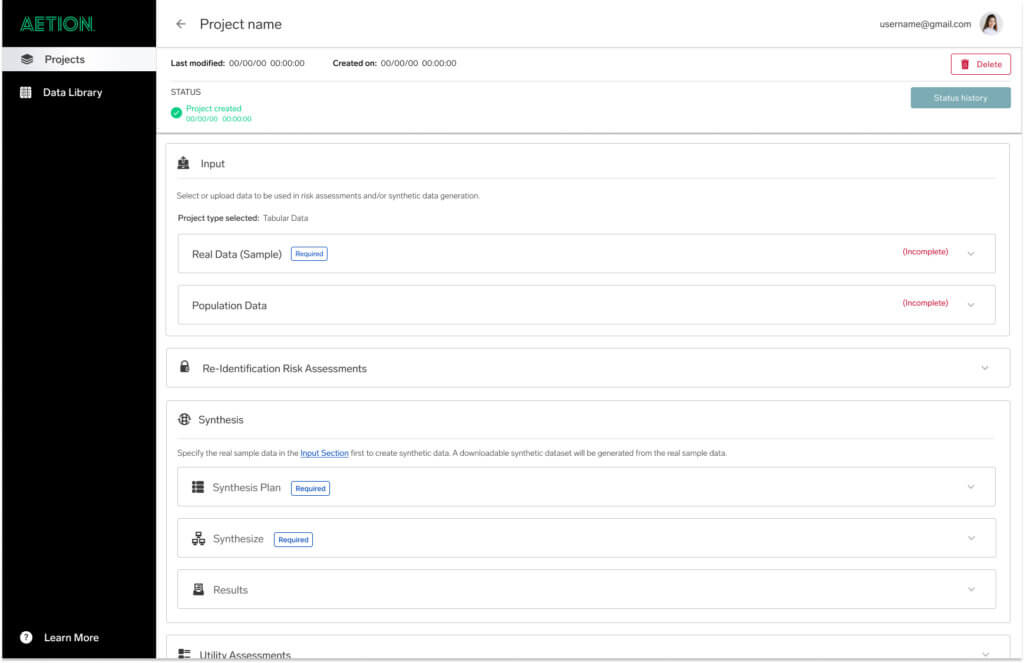
Assess, synthesize, and get more from your real-world and clinical data
With Generate, you’re ready to protect, share, reuse, amplify, and augment your sensitive data. And with the best in high security and high utility at high speed, you can get data otherwise untapped.
Protect precious modeling time with properly constructed data
Detect and resolve re-identification risks
Access and share otherwise inaccessible data
Amplify and augment datasets to address size, gaps, and balance
Assess and support data privacy
Assess privacy risk of standalone or linked data and inform expert determinations; apply findings to transform data and reduce risk.
Turn around results at a fraction of the time needed with legacy de-identification solutions.
Create synthetic data sets for enterprise leverage
Synthesize data from RWD, RCT, and other sources and share with confidence across and beyond the enterprise.
Drive business value— accelerate software testing, data and AI modeling, insights and more.
Create synthetic data sets to enhance existing data
Deploy Generate to bolster data in size or completeness.
Identify data bias, amplify and augment data—enhance utility toward new or greater insights and outcomes.
Synthetic data for real advantage
Today’s real challenges require ever evolving capabilities in real-world data, insights, and evidence. Synthetic data generation is the next step in your real-world strategy.
Synthetic data generation uses generative AI to produce privacy-preserved, statistically similar datasets from existing data. The data generated can be used and shared for research, and provide additional security to enable access, collaboration, and results that may not have otherwise been possible.
What’s more, unlike traditional de-identification mechanisms, synthesized data generation enables the retention of attributes and results that would otherwise be removed or obfuscated.
0%
From Gartner: “By 2024, 60% of the data used for the development of AI and analytics projects will be synthetically generated”
This 2021 Gartner projection covers all industries. Life sciences is moving with appropriate care in its adoption, and yet at a pace unimaginable before the COVID-19 pandemic.
Assess, synthesize, and get more from your real-world and clinical data
Aetion Generate uses evidence-based generative AI to protect, share, reuse, amplify, and augment your sensitive data assets. With the best in privacy and utility technology at high speed, you can get data otherwise untapped.
Privacy Assurance: Risk assessment methodology and results are outlined in a detailed report
Cloud or on-premise with cost effective auto-scaling capabilities that can be used in your environment
Cloud Platforms we support: Google Cloud, AWS, and Microsoft Azure
Three front ends:Generate UI, Python Software Development Kit (SDK support multiple data science and software engineering end-users), and APIs
The addition of Replica technology to our portfolio empowers our customers with greater access to the rich information in real-world datasets needed to accelerate scientific findings.
Our recent article in Scientific Reports shares how synthetic data generation can help address the data sharing challenges inherent in international collaboration.
To gain insights only multi-modal data can reveal, organizations must meet the requirements of the HIPAA Expert Determination Method. This on-demand webinar covers the intricacies of de-identifying complex data.