
The following article was published by OneTrust DataGuidance and can be accessed on their platform via subscription. Reprinted with permission.
Synthetic data is data that has been generated artificially, rather than being real-world data. In part one of this series on synthetic data, Dr. Khaled El Emam, SVP and General Manager of Replica Analytics Ltd, discusses what exactly this type of data is and how it is created. Future articles will discuss the specific use cases for synthetic data in more detail and provide examples from various industries.
Generative artificial intelligence ('AI') has been discussed in the media extensively, and therefore, people may have some awareness of it. It is a kind of machine learning technology that has given the world 'Space Opera Theatre', a digital painting that won the Colorado State Fair fine arts competitions (to great controversy). It is also the same technology that has provided for deep fakes, which are very realistic images of machine-generated, human faces. According to a report by the Proceedings of the National Academy of Sciences on the United States of America 1, members of the public have difficulty distinguishing between real and fake facial images, and find the fake ones more trustworthy.
The same underlying approach that is used to generate synthetic data. The 'data' here refers to tabular data, such as what can be seen in spreadsheets, electronic health records, and financial transactions. The first step is to train a machine learning model using existing real data. The machine learning model learns the patterns that exist in the real data. This machine learning model is called a generative model. Then, new data can be generated from these models. The models have become quite good at capturing subtle relationships in the real data, and therefore the generated synthetic data retains many of the characteristics of the original data, enabling users to draw the same conclusions.
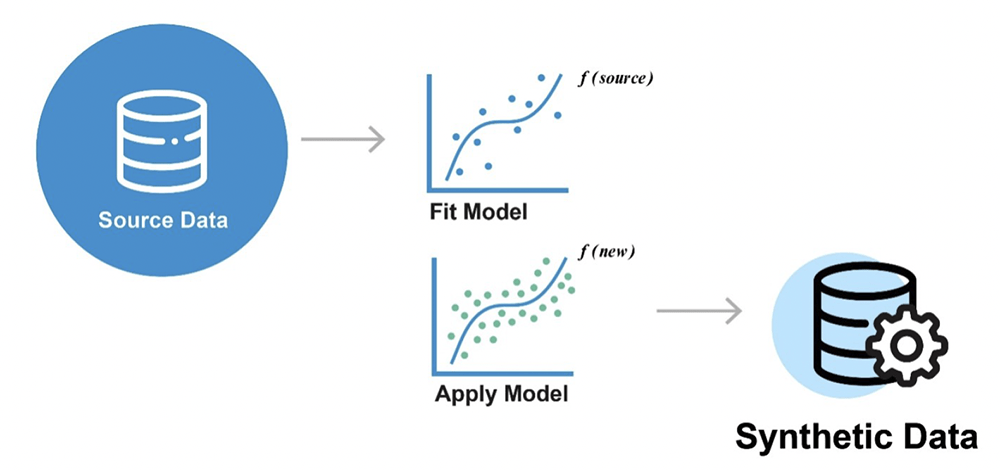 Source: Replica Analytics Ltd
Source: Replica Analytics Ltd
Many machine learning methods have been used to generate synthetic data. The choice of method will depend on the characteristics of the dataset. For example, data from a survey that fits into a single spreadsheet can be modeled very well using statistical methods. Whereas complex data from a hospital electronic health records system will require more sophisticated deep learning techniques to model. Therefore, the right modeling tools need to be used for each circumstance.
As there is not a one-to-one mapping between the generated data and the real data, the synthetic data tends to have strong privacy preserving properties. This means that the ability to match a synthetic record to a real person is significantly diminished if the synthetic data is generated using proper methods. Of course, if the synthetic data just replicates the original data, then it will be possible to match synthetic records with real people, but this should not happen, and is what we mean by 'proper'.
Synthetic data is a form of non-identifiable information that can be used and disclosed with significantly reduced obligations (such as the need to be obtain consent). These reduced obligations will vary by jurisdiction. However, in general, non-identifiable data is incentivised by reducing obligations and enabling easier unanticipated use and sharing of that data. There are multiple metrics that have been developed to evaluate in an objective way what the privacy risks are in synthetic data.
The metrics capture the different types of disclosures that can occur from synthetic data and quantify their likelihood of being successful. Various benchmarks have been developed as well to determine whether the risk values are acceptably small, using norms that have emerged over time.
In general, there are two classes of user stakeholders for synthetic data. Firstly there is the privacy community that sees synthetic data generation ('SDG') as a privacy enhancing tool. Secondly, there are the data users, who may be, for example, data analysts. The former are interested in the lower disclosure risk characteristics of synthetic data, and the latter are interested in ensuring the high utility of the synthetic data. Both sets of stakeholder requirements need to be addressed to ensure further adoption of SDG methods within an organisation.
There is a trade-off between privacy and utility in synthetic data. The greater the privacy the less the utility, and vice versa. Therefore, the generative models need to balance these two criteria to ensure that both are simultaneously optimised, and that an acceptable trade-off is achieved. Typically, a privacy threshold is established and as long as the privacy risk is below the threshold, the utility is maximised.
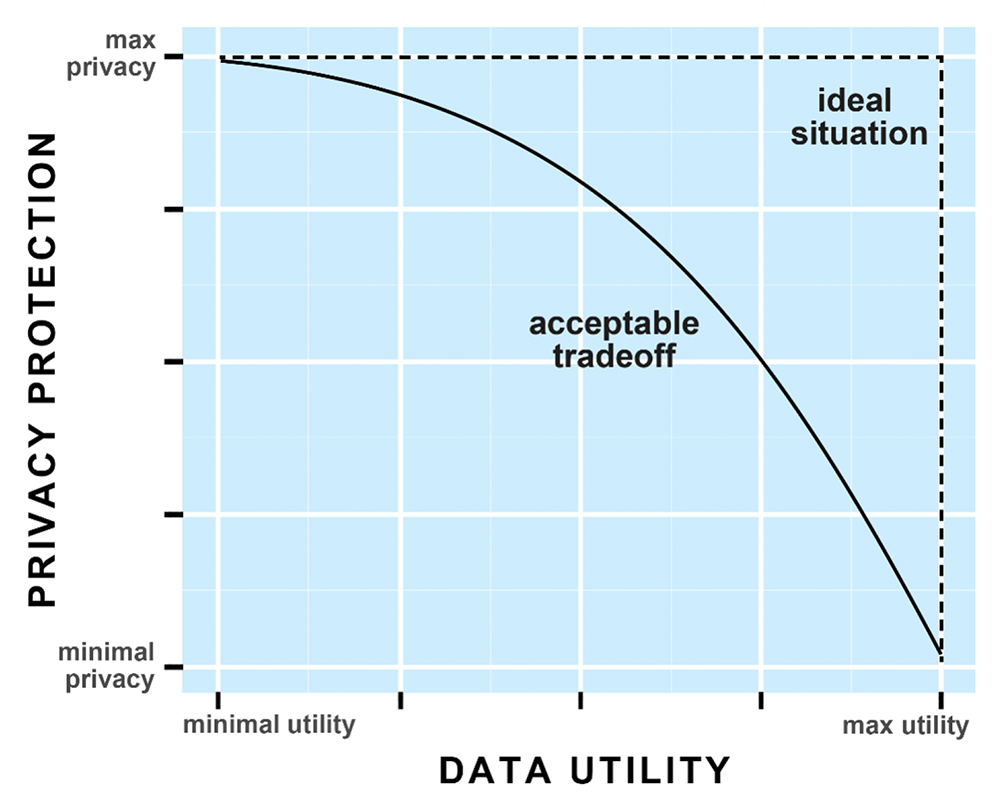 Source: Replica Analytics Ltd
Source: Replica Analytics Ltd
When a synthetic dataset is generated, it is common to produce a privacy report and a utility report. The privacy report documents the privacy metrics on the generated synthetic data. The utility report document show good the synthetic data is (its quality). These types of reports should be generated automatically as part of the SDG process and provide the users with the information they need to feel confident applying the generated data. 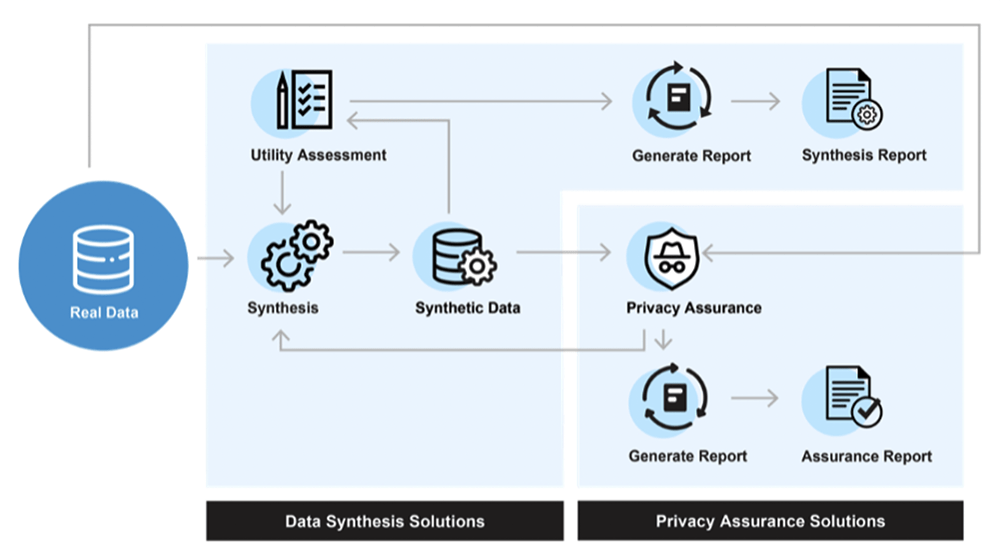 Source: Replica Analytics Ltd
Source: Replica Analytics Ltd
Given the on-going re-identification attacks that are being regularly reported on, there is a general concern about traditional de-identification and anonymisation methods. SDG is seen as a more reliable and more modern approach to protect data. Furthermore, the generation of synthetic data can be largely automated whereas traditional de-identification and anonymisation methods require significant expertise to apply properly. This is expertise that is often hard to find. Therefore, there are some practical advantages to creating synthetic data.
SDG has some limitations. For example, extremely rare events are more difficult to capture in the generative models. This is a general modelling challenge and not specific to generative models. Also, synthetic data does not provide zero disclosure risk. There is always some residual risk, but it would be very small if SDG is performed properly. This is going to be the case with any privacy enhancing technology. The relevant question is what does 'very small' mean and how can it be justified. Fortunately, there are defensible precedents to establish such thresholds.
Business and technology analysts have made broad statements about the adoption of SDG. While the exact quantitative projections may be questioned, their predictions are directionally consistent with our observations on the rapid adoption of this technology. SDG is becoming an important privacy enhancing technology for organisations to enable them to responsibly use and disclose datasets for secondary purposes.
Dr. Khaled El Emam SVP and General Manager kelemam@replica-analytics.com Replica Analytics Ltd, Ottawa