
The Expert Determination method is one of two methods for ensuring that a dataset is indeed de-identified described in the HIPAA Privacy Rule. The other method is Safe Harbor (see Figure 1). Once a dataset is de-identified using one of these methods, it can be used and disclosed for secondary purposes without having to obtain additional authorization or consent from the patients. 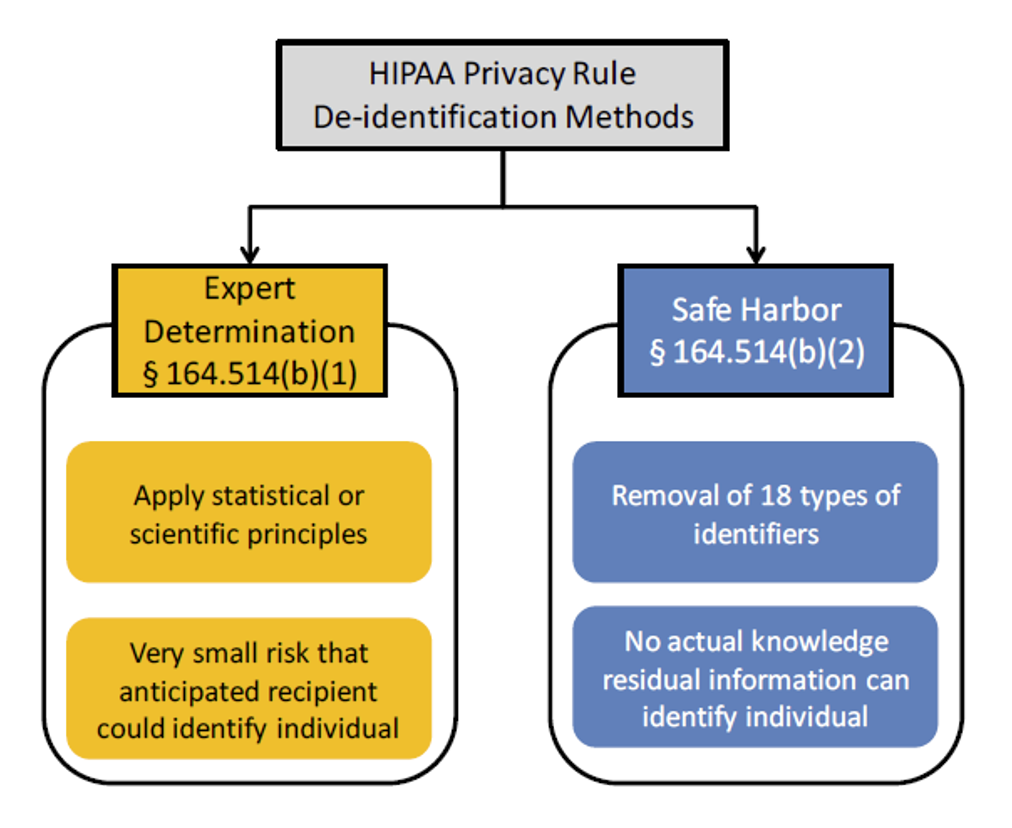
Figure 1: The two de-identification methods defined in the HIPAA Privacy Rule (from HHS Guidance).
The Expert Determination method is considered to be superior to Safe Harbor in that a dataset can have a high risk of re-identification and still meet the Safe Harbor requirements. However, the generally accepted statistical methods that are typically applied under the Expert Determination method will be more defensible in terms of ensuring a very small risk of re-identification.
The Expert Determination method is a good template for meeting the requirements for generating non-identifiable datasets in other jurisdictions, beyond the US, and for other types of data types, beyond health data. It embodies a set of good principles that reflect the practices in the statistical disclosure control community. Therefore, the general approach is arguably applicable beyond HIPAA.
The question we address here is whether synthetic data generation (SDG) can be used as a tool to meet the requirements of expert determination. We will start by defining the steps in Expert Determination as practiced (see Figure 2). 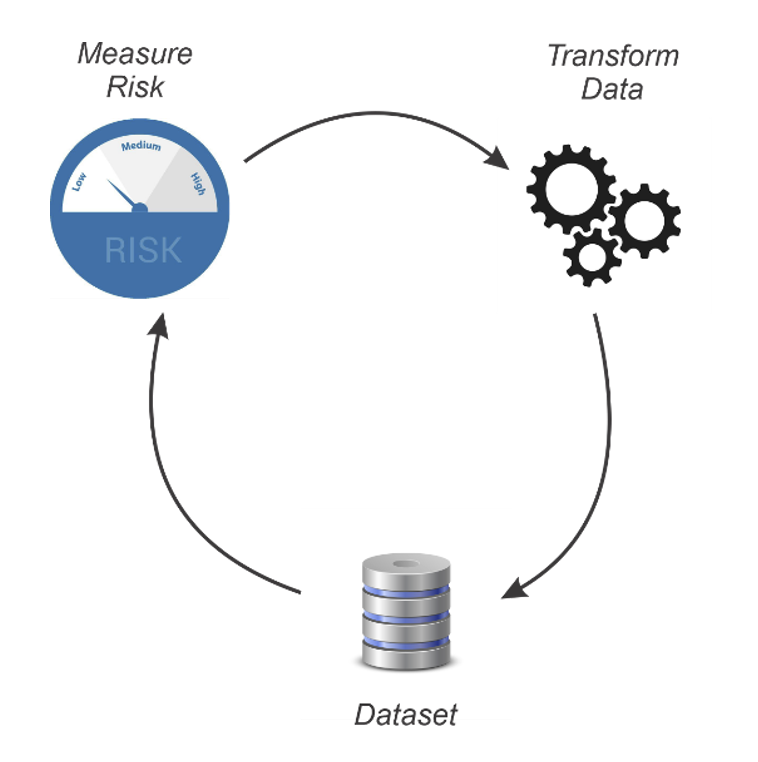 Figure 2 : The risk measurement and transformation cycle of de-identification.
Figure 2 : The risk measurement and transformation cycle of de-identification.
The first step is to measure the risk of re-identification. The second step is to transform the dataset to reduce that risk. Then risk is measured again. If the new risk measurement is below a pre-determined threshold then the data is deemed to be de-identified. If the risk is above the threshold, then the dataset is transformed again. This cycle repeats until the measured risk is below the threshold. For now, we will assume that the threshold is established a priori.
Common transformations that are applied include generalization, suppression, and the addition of noise. A key measure of privacy risk is identity disclosure, which is a measure of how likely it is that a record in the dataset can be correctly matched to a real person. This type of risk is commonly one that is relevant for de-identified datasets. And when the common transformations mentioned above are used, identity disclosure is the correct one to use to assess risk.
SDG can also be used to transform datasets. However, the concept of identity disclosure does not fit well with synthetic data because, if done well, there would not be a one-to-one mapping between the synthetic records and real people. There are other two types of privacy risk that are relevant for synthetic data: attribution disclosure and membership disclosure. These were already discussed in a previous article.
Therefore, SDG can be used to generate datasets that can operationalize the Expert Determination method, except that two different privacy metrics would be used instead of traditional identity disclosure risk metrics. The synthetic data that has low attribution and membership disclosure risk would be deemed to have a very small risk of re-identification, with a broader definition of re-identification to cover the three types of disclosures noted above.